
赛题背景
生物学年龄评价是一种通过测量和分析生物体内特定指标或生理过程的状态,以评估个体的生理年龄和健康状况的方法。与传统的日历年龄相比,生物学年龄可以提供更准确的健康评估和疾病风险预测。随着 AI 技术的不断发展,计算科学与生命科学的整合与发展将为健康管理应用开发、衰老机制研究、抗衰老药物研发提供前沿的思路与方法。基于上述背景,我们举办基于甲基化测量数据预测生物学年龄的比赛。
这项比赛将结合计算科学和生命科学的发展,为健康管理应用的开发、衰老机制的研究以及抗衰老药物的研发提供前沿的思路和方法。传统的日历年龄只提供了时间上的度量,而生物学年龄则更加关注个体的生理状态和功能。通过测量和分析生物体内的特定指标或生理过程的状态,我们能够更准确地评估个体的生理年龄和健康状况,这对于健康管理和疾病风险预测至关重要。参赛者可以利用甲基化测量数据来预测生物学年龄。本次比赛将为研究人员和开发人员提供机会,合作解决生物学年龄评估中的挑战,并推动相关领域的进步。最终的目标是提供更精确、可靠和个性化的生物学年龄评估工具,为人们的健康管理和抗衰老策略提供有力支持。
赛事任务
本次比赛提供健康人和年龄相关疾病患者的甲基化数据,期待选手通过分析甲基化数据的模式和特征建立预测模型,可以根据某个人的甲基化数据来预测其生物学年龄。
赛题数据集
公开数据包含10296个样本,其中7833个样本为健康样本。每一个样本提供485512个位点的甲基化数据、年龄与患病情况。抽取80%作为训练样本,20%作为测试样本。
以训练集为例,一共包括8233样本,其中健康样本6266个,其余为患病样本,共涉及Alzheimer’s disease,schizophrenia,Parkinson’s disease,rheumatoid arthritis,stroke,Huntington’s disease,Graves’ disease,type 2 diabetes,Sjogren’s syndrome等类型。
评价指标
本次任务采用多个指标来进行评测,初赛和复赛评价指标有差异,作为本次教程仅介绍初赛评价指标。初赛是将两个指标(健康样本MAE和患病样本MAE)进行计算,取平均得到最终分数。

解题思路
本题初赛任务是预测样本年龄,属于典型的回归问题。输入数据为每一个样本对应的485512个位点的甲基化数据与患病情况,输出为样本对应年龄。
特征处理
- 高维特征:所提供的特征纬度非常高(485512维),这为特征选择和处理带来了挑战。
- 特征选择:可以考虑基本的特征选择方法,如覆盖率、相关性、特征重要性等。
- 快速原型:为了快速验证模型效果,可以先仅使用部分特征快速跑通流程,后续再考虑如何添加更多特征。
模型选择
- 机器学习模型:如xgboost,这类模型不需要进行缺失值填充和数据标准化操作,效果比较稳定。
- 深度学习模型:需要进行缺失值填充和数据标准化操作,网络搭建也需要更多的尝试。
建议
鉴于上述对比,建议在Baseline中选择使用机器学习方法。在解决机器学习问题时,一般会遵循以下流程:
- 数据预处理:包括缺失值处理、异常值处理、数据标准化等。
- 特征工程:特征选择、特征构造、特征转换等。
- 模型选择:选择合适的模型进行训练。
- 模型训练:使用训练数据对模型进行训练。
- 模型验证:使用验证集评估模型的效果。
- 模型优化:根据验证结果对模型进行调优。
- 模型测试:使用测试集评估模型的最终效果。
官方Baseline代码解析
因为比赛官方提供了官方的baseline代码,所以我这一版本笔记先是给大家看下基础的baseline代码。
代码下载链接
pip install numpy pandas polars xgboost lightgbm catboost scikit-learn
首先,我们需要确保我们已经安装了所有必要的包。这些包是Baseline代码运行所必需的。
其次,我们将详细分析官方的Baseline代码。在这个过程中,我们会发现官方代码中的某些部分与我们通常的处理方式存在差别。这些差别可能是由于数据的特性、比赛的要求或其他原因造成的。我们将一一解析这些差别,并讨论其背后的原因。
先验证的笔记
数据处理
在处理生物学年龄评价的数据时,我们实际上是按照线性连续数据进行处理的,这意味着我们不需要具备生物信息经验。关键在于如何选择和处理特征。
特征选择的重要性
预测的准确性很大程度上取决于我们如何选择特征。以下是一些建议的步骤来进行特征选择:
- 去除低覆盖度的特征: 低覆盖度的特征可能不会为模型提供太多信息。因此,首先识别并去除这些特征是一个好的开始。
- 计算特征与年龄的相关性: 通过计算每个特征与年龄的相关性,我们可以对特征进行初步筛选。选择与目标变量(在这种情况下是年龄)高度相关的特征可以帮助提高模型的预测准确性。
- 去除冗余特征: 在某些情况下,两个或多个特征之间可能存在高度的相关性。这些特征可能会为模型提供相似或重复的信息。在这种情况下,保留一个特征并去除其他相关特征可以帮助减少模型的复杂性,并防止过拟合。
模型选择的考虑因素
- 数据的大小和维度: 对于大规模数据或高维数据,某些模型可能更适合,而其他模型可能会遇到性能问题。
- 问题的类型: 根据您的任务(分类、回归、聚类等),某些模型可能更适合。
- 模型的解释性: 在某些应用中,模型的解释性可能很重要。例如,决策树和线性回归提供了很好的解释性,而深度学习模型则较难解释。
- 训练时间: 某些模型可能需要更长的训练时间,特别是当数据集很大时。
- 预测时间: 在实时应用中,预测时间可能很关键。
常用的模型
- 线性模型: 如线性回归、逻辑回归。适用于关系大致是线性的数据。
- 决策树和随机森林: 适用于非线性关系的数据,提供了很好的解释性。
- 梯度提升机: 如XGBoost、LightGBM、CatBoost。这些模型通常在各种数据科学竞赛中表现出色。
- 支持向量机: 适用于分类和回归任务。
- 深度学习模型: 如神经网络。适用于大规模数据和复杂的非线性关系,特别是图像、文本和声音数据。
- K-最近邻: 一个简单的模型,适用于小型数据集。
- 朴素贝叶斯: 通常用于文本分类任务。
梯度提升决策树 (GBDT)
梯度提升决策树(Gradient Boosted Decision Trees,简称GBDT)是一种迭代的决策树算法,它通过加入新的树来纠正之前树的错误。GBDT是梯度提升方法与决策树算法的结合。
基本思想:
- Boosting:Boosting是一种集成学习方法,它的基本思想是将多个弱学习器组合成一个强学习器。在每一轮迭代中,Boosting方法都会为之前分类错误的样本增加更大的权重,然后训练一个新的学习器来纠正之前的错误。
- 梯度提升:梯度提升是一种迭代的方法,它通过计算损失函数的负梯度来更新模型。在每一轮迭代中,都会训练一个新的模型来拟合当前模型的负梯度(也称为残差或伪残差),然后将新模型的预测结果与当前模型的预测结果相加。
数学公式:
假设我们的损失函数为
\(L(y, F(x))\) 其中 ( y ) 是真实值, ( F(x) ) 是模型的预测值。
在每一轮迭代中,我们首先计算每个样本的负梯度(残差): \(r_i = -\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\)
然后,我们训练一个决策树来拟合这些残差。假设该决策树的预测结果为 ( h(x) ),我们可以通过以下公式来更新模型: \(F(x) = F(x) + \alpha \cdot h(x)\) 其中, ( \alpha )是学习率,它是一个小的正数,用于控制每一步的更新幅度。
这个过程会重复多次,直到满足某个停止准则(例如达到最大迭代次数或损失函数的值小于某个阈值)。
特点:
- GBDT可以用于分类和回归问题。
- GBDT对异常值和非线性关系都有很好的鲁棒性。
- GBDT可以自动处理缺失值和类别特征,不需要进行特征工程。
- CatBoost是GBDT的一种变种,它特别适合处理类别特征,因为它使用了一种特殊的编码方法来处理类别特征,从而避免了独热编码带来的维度爆炸问题。
增加一个一个对于梯度决策树的理解,因为我们常识中决策通常用来处理分类问题也就是不连续的问题
1 决策树如何开始训练的?
特征选择:遍历所有的特征。 切分点选择:对于当前特征,遍历所有可能的切分点。 计算误差:使用当前特征和切分点将数据分为两部分,并计算误差或不纯度。 选择最佳组合:记录下误差最小(或不纯度最小)的特征和切分点组合。 分裂节点:使用最佳的特征和切分点组合分裂当前节点,并为左右子节点重复上述过程。 这个过程会持续进行,直到满足某些停止条件,如树的最大深度、节点中的最小样本数等。 值得注意的是,每次分裂都是基于当前节点的数据进行的,这意味着随着树的深入,每个节点所处理的数据量会逐渐减少。这也是为什么决策树容易过拟合的原因之一,因为当树深入到某个程度时,每个节点可能只处理很少量的数据,导致模型过于复杂。这也是为什么通常需要对决策树进行剪枝或设置最大深度等约束的原因。
2 决策树如何处理回归问题?
在决策树和梯度提升决策树(GBDT)中,叶子节点的输出取决于我们正在解决的问题类型:
回归问题:对于回归树,叶子节点的输出是该节点上所有训练样本的目标值的平均值。例如,如果一个叶子节点包含了目标值为3, 4, 5的三个样本,那么该叶子节点的输出值将是(3+4+5)/3 = 4。
分类问题:对于分类树,叶子节点的输出通常是该节点上最常见的类别标签,或者是各个类别的概率分布。例如,如果一个叶子节点包含了10个样本,其中7个是类别A,3个是类别B,那么该叶子节点可能直接输出类别A,或者输出类别A的概率为0.7,类别B的概率为0.3。
在GBDT中,情况略有不同。GBDT是一个加法模型,每一棵树都在尝试纠正前面树的预测误差。因此,每棵树的叶子节点输出的是一个修正值,而不是直接的预测值。这些修正值会被加到前面树的预测结果上,从而逐步改进整体模型的预测性能。
总之,叶子节点的输出取决于问题类型(回归或分类)以及所使用的具体算法(普通决策树还是GBDT)。
例子–解释回归树的工作原理。
假设我们有以下数据集,我们想预测一个人的体重(目标值)基于他们的身高(特征):
身高 (cm) | 体重 (kg)
---------------------
150 | 45
155 | 48
160 | 52
165 | 56
170 | 60
现在,假设我们构建一个简单的回归树,只有一个决策节点和两个叶子节点。决策节点的条件是“身高 < 160cm”。
这意味着,所有身高小于160cm的数据点都会走到左边的叶子节点,而其他的则会走到右边的叶子节点。
左叶子节点包含的数据点:
150 | 45
155 | 48
右叶子节点包含的数据点:
160 | 52
165 | 56
170 | 60
对于回归树,叶子节点的输出是该节点上所有训练样本的目标值的平均值。
所以,左叶子节点的输出值是 (45 + 48) / 2 = 46.5 kg 右叶子节点的输出值是 (52 + 56 + 60) / 3 = 56 kg
这意味着,当我们使用这棵树来预测一个身高为157cm的人的体重时,预测结果将是46.5kg。而对于身高为167cm的人,预测结果将是56kg。
这只是一个非常简单的例子,实际的回归树可能会有更多的决策节点和叶子节点,以及更复杂的决策条件。但是,无论树的结构如何,每个叶子节点的输出值都是基于该节点上的训练样本的目标值的平均值确定的。
3 GBDT多树如何训练,以及iterations参数?
细节参数在这个baseline 代码中 提供了一个 iterations 最大树,其实就是要训练500个树。在这个是怎么训练的呢,其实不是大家节点一起顺利,而是顺利好一颗后顺利第二个,子节点输出均值来代表当前输出.
- 初始化模型:开始时,模型可能只是一个常数值,例如所有目标值的平均数。
- 构建第一棵树:使用训练数据构建第一棵决策树。这棵树会尝试预测目标值(对于第一棵树,这就是原始的目标值)。
- 计算残差:使用第一棵树对训练数据进行预测,并计算预测值与真实值之间的差异(残差)。
- 构建第二棵树:现在,我们使用相同的训练数据构建第二棵树,但这次我们的目标是预测第一棵树的残差,而不是原始的目标值。
- 累积预测:为了得到最终的预测,我们首先使用第一棵树进行预测,然后加上第二棵树的预测(这实际上是预测的残差)。
- 重复:我们继续这个过程,每次都构建一个新的树来预测前一棵树的残差,并将所有树的预测累加起来,直到达到指定的树的数量(在这个baseline代码中是500)。
4 树结构深度转化是如何计算的?
最大节点数: 对于深度为 (d) 的二叉树(每个节点都有两个子节点,这是决策树的常见情况),其最大节点数为: \(\text{最大节点数} = 2^{(d + 1)} - 1\)
最大叶子节点数: 对于深度为 (d) 的二叉树,其最大叶子节点数为: \(\text{最大叶子节点数} = 2^d\)
最小深度: 给定节点数 (n),二叉树的最小深度为: \(\text{最小深度} = \log_2(n + 1)\)
5 CatBppst默认参数?
通用参数:
loss_function 损失函数,支持的有RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE,Poisson。默认RMSE。
custom_metric 训练过程中输出的度量值。这些功能未经优化,仅出于信息目的显示。默认None。
eval_metric 用于过拟合检验(设置True)和最佳模型选择(设置True)的loss function,用于优化。
iterations 最大树数。默认1000。
learning_rate 学习率。默认0.03。
random_seed 训练时候的随机种子
l2_leaf_reg L2正则参数。默认3
bootstrap_type 定义权重计算逻辑,可选参数:Poisson (supported for GPU only)/Bayesian/Bernoulli/No,默认为Bayesian
bagging_temperature 贝叶斯套袋控制强度,区间[0, 1]。默认1。
subsample 设置样本率,当bootstrap_type为Poisson或Bernoulli时使用,默认66
sampling_frequency设置创建树时的采样频率,可选值PerTree/PerTreeLevel,默认为PerTreeLevel
random_strength 分数标准差乘数。默认1。
use_best_model 设置此参数时,需要提供测试数据,树的个数通过训练参数和优化loss function获得。默认False。
best_model_min_trees 最佳模型应该具有的树的最小数目。
depth 树深,最大16,建议在1到10之间。默认6。
ignored_features 忽略数据集中的某些特征。默认None。
one_hot_max_size 如果feature包含的不同值的数目超过了指定值,将feature转化为float。默认False
has_time 在将categorical features转化为numerical
features和选择树结构时,顺序选择输入数据。默认False(随机)
rsm 随机子空间(Random subspace method)。默认1。
nan_mode处理输入数据中缺失值的方法,包括Forbidden(禁止存在缺失),Min(用最小值补),Max(用最大值补)。默认Min。
fold_permutation_block_size数据集中的对象在随机排列之前按块分组。此参数定义块的大小。值越小,训练越慢。较大的值可能导致质量下降。
leaf_estimation_method 计算叶子值的方法,Newton/ Gradient。默认Gradient。
leaf_estimation_iterations 计算叶子值时梯度步数。
leaf_estimation_backtracking 在梯度下降期间要使用的回溯类型。
fold_len_multiplier folds长度系数。设置大于1的参数,在参数较小时获得最佳结果。默认2。
approx_on_full_history 计算近似值,False:使用1/fold_len_multiplier计算;True:使用fold中前面所有行计算。默认False。
class_weights 类别的权重。默认None。
scale_pos_weight 二进制分类中class 1的权重。该值用作class 1中对象权重的乘数。
boosting_type 增压方案
allow_const_label 使用它为所有对象训练具有相同标签值的数据集的模型。默认为False
6 关于内存压缩怎么做的?
在这个baseline中reduce_mem_usage 函数通过检查每一列的数据范围,然后尝试将其转换为更小的数据类型来减少内存使用。例如,如果一个整数列的所有值都在 int8 的范围内,那么该列就会被转换为 int8 类型,从而节省内存
关于其他高度压缩的数据格式:HDF5 和 Parquet 是两种常用的高度压缩的数据格式。它们都支持列式存储,这使得读取单个列非常快速,而不需要加载整个数据集。这对于大数据工作流非常有用,特别是当你只需要处理数据的一小部分时。
7 pickle 是什么数据?
pickle 是 Python 中用于序列化和反序列化对象的一个模块。通过序列化,你可以将几乎任何 Python 对象转换为一个字节流,然后将其保存到磁盘或通过网络发送。反序列化则是将这个字节流转回原始的 Python 对象。
与 csv 相比,pickle 和 csv 有以下主要区别:
- 数据类型:
- pickle:可以存储几乎所有的 Python 对象,包括但不限于字典、列表、自定义对象、函数等。
- csv:主要用于存储表格数据,每一行是一个记录,每个字段由逗号分隔(或其他分隔符)。
- 安全性:
- pickle:不安全,因为它可以执行任意代码。你不应该反序列化来自不可信来源的数据。
- csv:相对安全,因为它只是纯文本数据。
- 可读性:
- pickle:生成的是二进制格式,人类通常无法直接阅读。
- csv:是纯文本格式,可以使用任何文本编辑器查看。
- 兼容性:
- pickle:特定于 Python,其他编程语言可能无法直接读取。
- csv:是一个通用格式,可以被许多应用程序和编程语言读取。
- 用途:
- pickle:当你想保存一个 Python 对象的完整状态,以便稍后恢复它时,使用 pickle 是很有用的。例如,机器学习模型经常被保存为 pickle 文件。
- csv:当你有表格数据并且想与其他应用程序(如电子表格软件)或编程语言共享时,使用 csv 是很有用的
补充其他数据格式,压缩数据格式:
还有许多其他的数据存储格式,特别是在数据科学和机器学习领域。以下是一些常见的格式:
- HDF5 (Hierarchical Data Format version 5) / H5:
- 描述:HDF5 是一个用于存储大量数据的文件格式和库。它可以存储多种类型的数据,包括图像、数组和表格。
- 优点:支持大数据集,高度压缩,跨平台,支持并发读写。
- 用途:常用于大规模数据存储,如卫星数据、粒子物理数据等。
- Python 工具:
h5py和pandas都提供了对 HDF5 格式的支持。
- Parquet:
- 描述:是一个列式存储格式,特别适合大数据处理工具如 Apache Spark 和 Apache Drill。
- 优点:高度压缩,性能优化,支持嵌套数据结构。
- 用途:大数据处理和存储。
- Python 工具:
pyarrow和fastparquet。
- Feather:
- 描述:是一个跨语言的列式存储文件格式。它是为了在数据科学工作流中快速读写数据而设计的。
- 优点:快速读写,轻量级,支持多种数据类型。
- 用途:数据科学工作流中的中间数据存储。
- Python 工具:
pyarrow。
- Protocol Buffers (protobuf):
- 描述:由 Google 开发的一种数据序列化格式。
- 优点:小巧、快速、简单。
- 用途:跨平台、跨语言的数据交换。
- Python 工具:Google 提供的
protobufPython API。
- Joblib:
- 描述:是一个 Python 库,用于轻松保存和加载 Python 对象,特别是大型 NumPy 数组。
- 优点:对 NumPy 数据有优化,快速。
- 用途:保存机器学习模型、大型数据。
- Python 工具:
joblib。
- MessagePack:
- 描述:是一个高效的二进制序列化格式。
- 优点:小巧、快速、与 JSON 类似但更紧凑。
- 用途:数据交换、存储。
- Python 工具:
msgpack-python。
精读Baseline 这个baseline的解决方法就是利用的
导入模块
导入我们本次Baseline代码所需的模块
# 导入numpy库,用于进行数值计算
import numpy as np
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入polars库,用于处理大规模数据集
import polars as pl
# 导入collections库中的defaultdict和Counter,用于统计
from collections import defaultdict, Counter
# 导入xgboost库,用于梯度提升树模型
import xgb
# 导入lightgbm库,用于梯度提升树模型
import lgb
# 导入CatBoostRegressor库,用于梯度提升树模型
from catboost import CatBoostRegressor
# 导入StratifiedKFold、KFold和GroupKFold,用于交叉验证
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
# 导入mean_squared_log_error,用于评估模型性能
from sklearn.metrics import mean_squared_log_error
# 导入sys、os、gc、argparse和warnings库,用于处理命令行参数和警告信息
import sys, os, gc, argparse, warnings
# 均绝对误差)是一个用于回归问题评估模型性能的指标之一,它衡量了预测值与实际观测值之间的平均绝对差异。
from sklearn.metrics import mean_absolute_error
# 忽略警告信息
warnings.filterwarnings('ignore')
数据探索
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
加载数据及基本的预处理,需要特别注意:
训练集压缩包7.22G,测试集压缩包2.01G

解压缩后traindata.csv56.7G,testdata.csv压缩包14.2G
本地算力不够的同学,推荐使用赛事云端环境PAI-DSW
1、使用reduce_mem_usage_pl函数对数据进行类型转换,及时减少内存;下面代码中使用压缩函数,内存可以压缩一半;
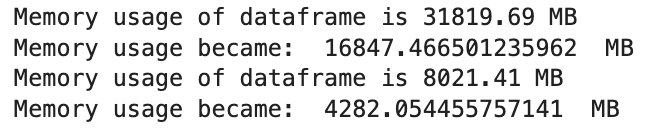
2、对数据进行预处理,主要是进行数据表的转置操作,因为原本数据为每一列代表一个样本,需要调整为每一行为一个样本;
3、处理完的数据然后保存为pickle文件,之后使用数据时可以直接加载pickle文件即可,减少重复预处理工作。
# 定义一个函数,用于减少DataFrame的内存使用
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64'] # 定义数值类型列表
start_mem = df.memory_usage().sum() / 1024**2 # 计算初始内存使用量
for col in df.columns: # 遍历DataFrame的每一列
col_type = df[col].dtypes # 获取该列的数据类型
if col_type in numerics: # 如果该列是数值类型
c_min = df[col].min() # 获取该列的最小值
c_max = df[col].max() # 获取该列的最大值
if str(col_type)[:3] == 'int': # 如果该列是整数类型
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: # 如果该列的数值范围在int8的范围内
df[col] = df[col].astype(np.int8) # 将该列的数据类型转换为int8
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: # 如果该列的数值范围在int16的范围内
df[col] = df[col].astype(np.int16) # 将该列的数据类型转换为int16
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: # 如果该列的数值范围在int32的范围内
df[col] = df[col].astype(np.int32) # 将该列的数据类型转换为int32
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: # 如果该列的数值范围在int64的范围内
df[col] = df[col].astype(np.int64) # 将该列的数据类型转换为int64
else: # 如果该列不是整数类型
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: # 如果该列的数值范围在float16的范围内
df[col] = df[col].astype(np.float16) # 将该列的数据类型转换为float16
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: # 如果该列的数值范围在float32的范围内
df[col] = df[col].astype(np.float32) # 将该列的数据类型转换为float32
else: # 如果该列的数值范围不在上述三种类型的范围内
df[col] = df[col].astype(np.float64) # 将该列的数据类型转换为float64
end_mem = df.memory_usage().sum() / 1024**2 # 计算结束时的内存使用量
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem)) # 输出内存使用量的减少情况
return df # 返回处理后的DataFrame
# 读取数据
path = 'ai4bio' # 定义数据集路径
# 可能因为内存问题所导致数据读取困难,可以选择放弃部分特征,仅读取部分行,baseline仅读取前10000行
#根据自己的算力情况,适当读取数据
traindata = pd.read_csv(f'{path}/traindata.csv', nrows=10000) # 读取训练数据
trainmap = pd.read_csv(f'{path}/trainmap.csv') # 读取训练数据的映射信息
testdata = pd.read_csv(f'{path}/ai4bio_testset_final/testdata.csv', nrows=10000) # 读取测试数据
testmap = pd.read_csv(f'{path}/ai4bio_testset_final/testmap.csv') # 读取测试数据的映射信息
# 压缩内存,因时间较长,所以暂时注释掉,按自身情况选择使用
# traindata = reduce_mem_usage(traindata)
# testdata = reduce_mem_usage(testdata)
# 数据预处理
traindata = traindata.set_index('cpgsite') # 将训练数据的索引设置为'cpgsite'列
traindata = traindata.T # 转置训练数据
traindata = traindata.reset_index() # 重置训练数据的索引
traindata = traindata.rename(columns={'index':'sample_id'}) # 重命名训练数据的列名
traindata.columns = ['sample_id'] + [i for i in range(10000)] # 设置训练数据的列名为'sample_id'加上一列自增的数字
traindata.to_pickle(f'{path}/traindata.pkl') # 将处理后的训练数据保存为pickle文件
testdata = testdata.set_index('cpgsite') # 将测试数据的索引设置为'cpgsite'列
testdata = testdata.T # 转置测试数据
testdata = testdata.reset_index() # 重置测试数据的索引
testdata = testdata.rename(columns={'index':'sample_id'}) # 重命名测试数据的列名
testdata.columns = ['sample_id'] + [i for i in range(10000)] # 设置测试数据的列名为'sample_id'加上一列自增的数字
testdata.to_pickle(f'{path}/testdata.pkl') # 将处理后的测试数据保存为pickle文件
基本信息展示
# 使用 head() 函数查看前几行数据
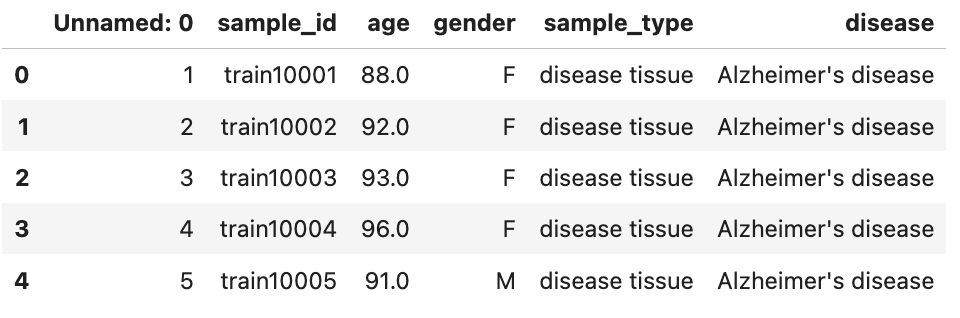
trainmap.head()
# 使用 head() 函数查看前几行数据
traindata.head()

# info()的方法,用于显示有关数据集的信息,例如列名、数据类型、非空值数量和内存使用情况等。
traindata.info()

经过上面简单的信息展示,可以发现trainmap中的gender、sample_type、disease为字符串类型的特征,需要进行转换为数值类型。traindata数据已经调整为每行代表一个样本的结构,每列表示一个特征。
下面展示部分特征字段地缺失比例,可以看出部分特征缺失率还是蛮高的。
# 使用循环来遍历数据集traindata的前10个特征,并计算每个特征的缺失率。
for i in range(10):
# 使用traindata[i]获取第i个特征的数据,调用isnull()方法来判断数据是否为空值,返回一个布尔类型的数组,使用sum()方法对布尔数组求和,统计每行中空值的数量,将空值数量除以数据集的总行数,得到该特征的缺失率。
null_cnt = traindata[i].isnull().sum() / traindata.shape[0]
# 使用print()函数输出特征名称和对应的缺失率。
print(f'特征{i},对应的缺失率为{null_cnt}')

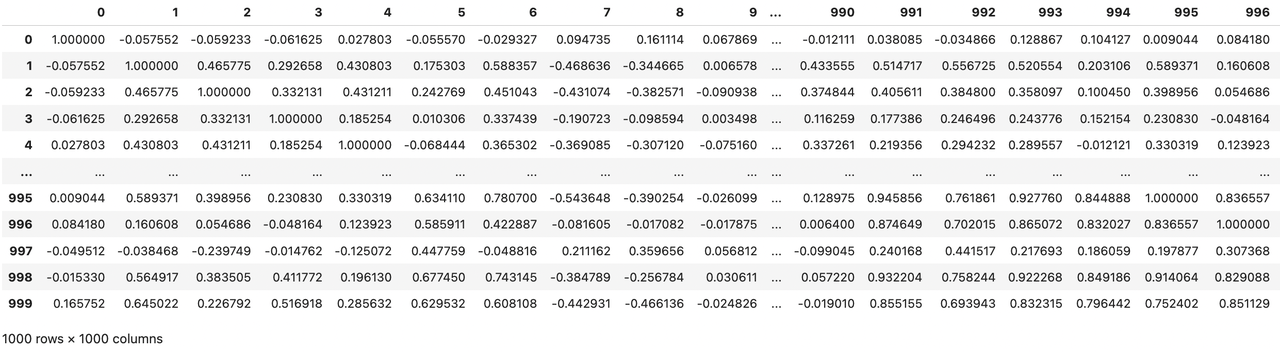
下面使用DataFrame自带的corr()方法展示前1000个特征之间的相关性分数,大于0为正相关,小于0为负相关。
# 代码使用列表推导式生成一个包含前1000个特征的列表,即[i for i in range(1000)],这个列表作为索引传递给traindata,以获取这些特征对应的列数据,调用corr()方法计算这些列之间的相关系数矩阵。
traindata[[i for i in range(1000)]].corr()
数据清洗
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。俗话说:garbage in, garbage out。分析完数据后,特征工程前,必不可少的步骤是对数据清洗。
数据清洗的作用是利用有关技术如数理统计、数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。主要包括缺失值处理、异常值处理、数据分桶、特征归一化/标准化等流程。
经过数据探索部分的分析,需要进行处理的部分包括缺失值、数据类型转换,其中对于缺失值的处理,鉴于baseline方案使用的是catboost模型,并不需要进行缺失值处理。
下面仅需要进行数据类型的转换操作:
# 数据拼接
# 将trainmap数据集中的'sample_id', 'age', 'gender', 'sample_type', 'disease'这几列数据合并到traindata数据集中,合并的依据是两个数据集中的'sample_id'列相同,合并后的结果存储在traindata中。
traindata = traindata.merge(trainmap[['sample_id', 'age', 'gender', 'sample_type', 'disease']],on='sample_id',how='left')
# 将testmap数据集中的'sample_id', 'gender'这两列数据合并到testdata数据集中,合并的依据是两个数据集中的'sample_id'列相同,合并后的结果存储在testdata中,由于使用了左连接(how='left'),如果testmap中没有与testdata匹配的'sample_id',那么对应的'gender'值将会被填充为NaN。
testdata = testdata.merge(testmap[['sample_id', 'gender']],on='sample_id',how='left')
# 定义了一个名为disease_mapping的字典,它将疾病名称映射为对应的数值。例如,'Alzheimer's disease'被映射为1,'Parkinson's disease'被映射为4,以此类推。这样的映射通常用于机器学习模型中的特征编码,以便将文本形式的类别标签转换为可以输入到模型的数字形式。
disease_mapping = {
'control': 0,
"Alzheimer's disease": 1,
"Graves' disease": 2,
"Huntington's disease": 3,
"Parkinson's disease": 4,
'rheumatoid arthritis': 5,
'schizophrenia': 6,
"Sjogren's syndrome": 7,
'stroke': 8,
'type 2 diabetes': 9
}
sample_type_mapping = {'control': 0, 'disease tissue': 1}
gender_mapping = {'F': 0, 'M': 1}
# 将traindata数据集中'disease'列中的疾病名称使用disease_mapping字典进行映射,将疾病名称替换为对应的数值。这样处理后,'disease'列中的值将变为0到9之间的整数。
traindata['disease'] = traindata['disease'].map(disease_mapping)
# 将traindata数据集中'sample_type'列中的样本类型使用sample_type_mapping字典进行映射,将样本类型替换为对应的数值,处理后,'sample_type'列中的值将变为0或1,表示不同的样本类型。
traindata['sample_type'] = traindata['sample_type'].map(sample_type_mapping)
# 将traindata和testdata数据集中'gender'列中的性别使用gender_mapping字典进行映射,将性别替换为对应的数值。这样处理后,'gender'列中的值将变为0或1,表示不同的性别。
traindata['gender'] = traindata['gender'].map(gender_mapping)
testdata['gender'] = testdata['gender'].map(gender_mapping)
特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
原始字段特征以连续型数值为主,可以按行进行聚合统计操作,如构建max、min、mean、std、skew等常见的数值统计特征。
# 特征工程
# 计算traindata和testdata数据集中前10000行每一列的最大值、最小值、标准差、方差、偏度、均值和中位数,并将结果分别存储在traindata和testdata的'max'、'min'、'std'、'var'、'skew'、'mean'和'median'列中,这些统计量可以用于描述数据集的特征和分布情况。
traindata['max'] = traindata[[i for i in range(10000)]].max(axis=1)
traindata['min'] = traindata[[i for i in range(10000)]].min(axis=1)
traindata['std'] = traindata[[i for i in range(10000)]].std(axis=1)
traindata['var'] = traindata[[i for i in range(10000)]].var(axis=1)
traindata['skew'] = traindata[[i for i in range(10000)]].skew(axis=1)
traindata['mean'] = traindata[[i for i in range(10000)]].mean(axis=1)
traindata['median'] = traindata[[i for i in range(10000)]].median(axis=1)
testdata['max'] = testdata[[i for i in range(10000)]].max(axis=1)
testdata['min'] = testdata[[i for i in range(10000)]].min(axis=1)
testdata['std'] = testdata[[i for i in range(10000)]].std(axis=1)
testdata['var'] = testdata[[i for i in range(10000)]].var(axis=1)
testdata['skew'] = testdata[[i for i in range(10000)]].skew(axis=1)
testdata['mean'] = testdata[[i for i in range(10000)]].mean(axis=1)
testdata['median'] = testdata[[i for i in range(10000)]].median(axis=1)
# 入模特征选择
cols = [i for i in range(10000)] + ['gender','max','min','std','var','skew','mean','median']
模型训练与验证
特征工程也好,数据清洗也罢,都是为最终的模型来服务的,模型的建立和调参决定了最终的结果。模型的选择决定结果的上限, 如何更好的去达到模型上限取决于模型的调参。
建模的过程需要我们对常见的线性模型、非线性模型有基础的了解。模型构建完成后,需要掌握一定的模型性能验证的方法和技巧
作为baseline方案使用catboost模型,并选择经典的K折交叉验证方法进行离线评估,大体流程如下:
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
4、最后将K折预测结果取平均作为最终提交结果。

具体代码如下:
# 模型训练与验证
# 定义一个名为catboost_model的函数,接收四个参数:train_x, train_y, test_x和seed
def catboost_model(train_x, train_y, test_x, seed = 2023):
folds = 5 # 设置K折交叉验证折数为5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed) # 使用KFold方法创建一个交叉验证对象kf,设置折数、是否打乱顺序和随机种子
oof = np.zeros(train_x.shape[0]) # 初始化一个全零数组oof,长度为train_x的长度
test_predict = np.zeros(test_x.shape[0]) # 初始化一个全零数组test_predict,长度为test_x的长度
cv_scores = [] # 初始化一个空列表cv_scores,用于存储交叉验证得分
# 使用for循环遍历kf的每个折叠
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
# 打印当前折数的序号
print('************************************ {} ************************************'.format(str(i+1)))
# 获取当前折叠的训练集索引和验证集索引,根据索引获取训练集和验证集的特征和标签
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
# 定义CatBoostRegressor模型的参数
params = {'learning_rate': 0.1, # 学习率,控制模型参数更新的速度。值越大,模型更新越快,但可能陷入局部最优解;值越小,模型更新越慢,但可能收敛到更好的解。
'depth': 5, # 树的深度,即决策树的最大层数。树的深度越深,模型的复杂度越高,可能导致过拟合;树的深度越浅,模型的复杂度越低,可能导致欠拟合。
'bootstrap_type':'Bernoulli', # 自助法的类型,用于有放回地抽样。'Bernoulli'表示使用伯努利分布进行抽样,每次抽样后将结果反馈到训练集中。
'random_seed':2023, # 随机种子,用于控制随机过程。设置相同的随机种子可以保证每次运行代码时得到相同的结果。
'od_type': 'Iter', # 迭代次数优化方法的类型。'Iter'表示使用迭代次数优化方法,通过多次迭代来寻找最优的迭代次数。
'od_wait': 100, # 迭代次数优化方法的等待时间,即两次迭代之间的最小间隔。设置较长的等待时间可以加快收敛速度,但可能导致过拟合;设置较短的等待时间可以加快收敛速度,但可能导致欠拟合。
'allow_writing_files': False, # 是否允许写入文件。设置为False表示不保存模型参数,只返回模型对象。
'task_type':"GPU", # 任务类型,表示模型运行在GPU还是CPU上。设置为"GPU"表示模型运行在GPU上,如果计算机没有GPU,可以设置为"CPU"。
'devices':'0:1' }# 设备列表,表示使用哪些GPU设备。"0:1"表示只使用第一个GPU设备。
# 创建CatBoostRegressor模型实例
# 根据自己的算力与精力,调整iterations,V100环境iterations=500需要跑10min
model = CatBoostRegressor(iterations=500, **params) # 这里的iterations指定了树的数目也就是500课数目
# 使用训练集和验证集拟合模型
model.fit(trn_x, trn_y, # 训练集的特征和标签,用于模型的训练。
eval_set=(val_x, val_y), # 验证集的特征和标签,用于在训练过程中评估模型性能。
metric_period=500, # 定评估指标的计算周期,即每隔多少次迭代计算一次评估指标。
use_best_model=True, # 设置为True表示在训练过程中使用验证集上性能最好的模型参数。
cat_features=[], # 包含需要转换为类别特征的特征名称,没有需要转换的特征,所以为空列表。
verbose=1) # 设置日志输出的详细程度,1表示输出详细信息。
# 使用模型对测试集进行预测
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
# 将验证集预测结果存储到oof数组中
oof[valid_index] = val_pred
# 计算K折测试集预测结果的平均值并累加到test_predict数组中
test_predict += test_pred / kf.n_splits
# 暂时忽略健康样本和患病样本在计算MAE上的差异,仅使用常规的MAE指标
# 计算验证集预测结果与真实值之间的平均绝对误差(MAE)
score = mean_absolute_error(val_y, val_pred)
# 将MAE添加到cv_scores列表中
cv_scores.append(score)
print(cv_scores) # 打印cv_scores列表
# 获取特征重要性打分,便于评估特征
if i == 0:
# 将特征名称和打分存储到DataFrame中
fea_ = model.feature_importances_
fea_name = model.feature_names_
fea_score = pd.DataFrame({'fea_name':fea_name, 'score':fea_})
# 按照打分降序排列DataFrame
fea_score = fea_score.sort_values('score', ascending=False)
# 将排序后的DataFrame保存为CSV文件(命名为feature_importances.csv)
fea_score.to_csv('feature_importances.csv', index=False)
return oof, test_predict # 返回oof和test_predict数组
# 调用catboost_model函数,进行模型训练与结果预测
cat_oof, cat_test = catboost_model(traindata[cols], traindata['age'], testdata[cols])
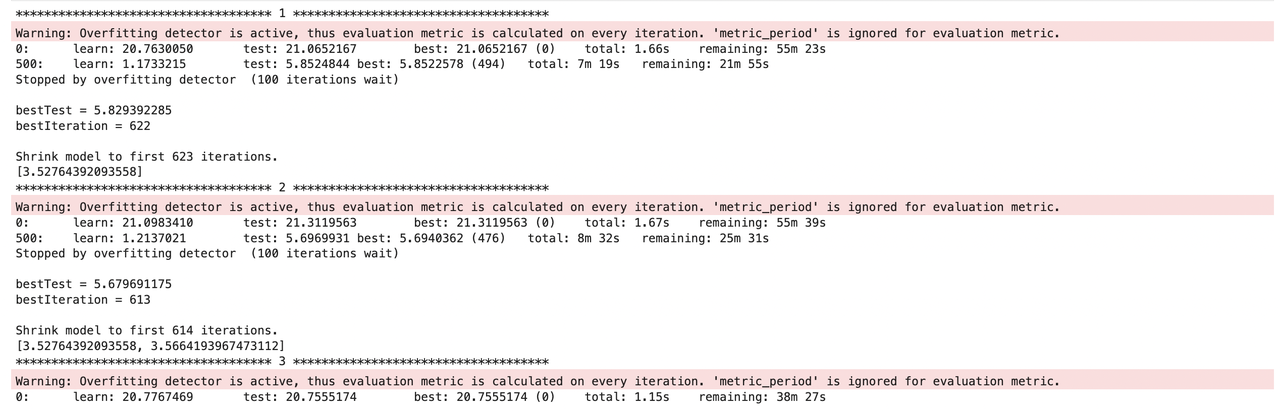
特征重要性结果展示:
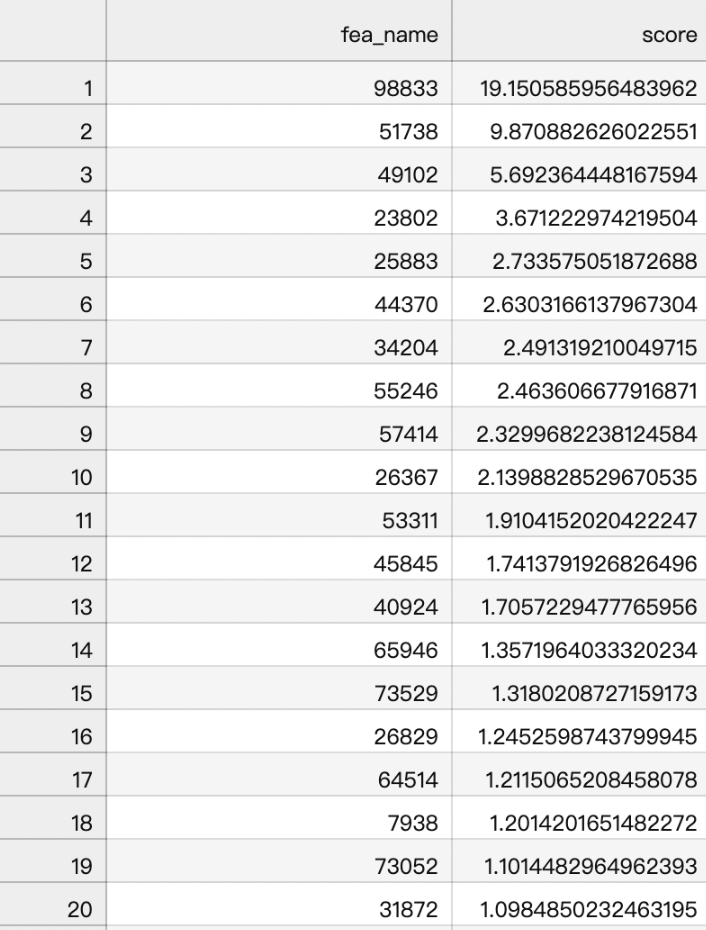
细致的观察特征重要性排序,我们手动构建的max、min、mean这类特征并没有排到前面,这也大概率说明这类特征可能没有太多作用。
结果输出
提交需要符合提交样例结果,线上提交分数3.8840,能优化的空间还是非常大的。
# 输出赛题提交格式的结果
testdata['age'] = cat_test # 将testdata数据框中的age列赋值为cat_test。
testdata['age'] = testdata['age'].astype(float) # 将age列的数据类型转换为浮点数。
testdata['age'] = testdata['age'].apply(lambda x: x if x>0 else 0.0) # 使用lambda函数对age列中的每个元素进行判断,如果大于0,则保持不变,否则将其替换为0.0。
testdata['age'] = testdata['age'].apply(lambda x: '%.2f' % x) # 使用lambda函数将age列中的每个元素格式化为保留两位小数的字符串。
testdata['age'] = testdata['age'].astype(str) # 将age列的数据类型转换为字符串。
testdata[['sample_id','age']].to_csv('submit.txt',index=False) # 将sample_id和age两列保存到名为submit.txt的文件中,不包含索引。
nrow:读取数据行数,iterations:模型迭代次数,阿里云PAI-DSW提供的最高配免费算力V100
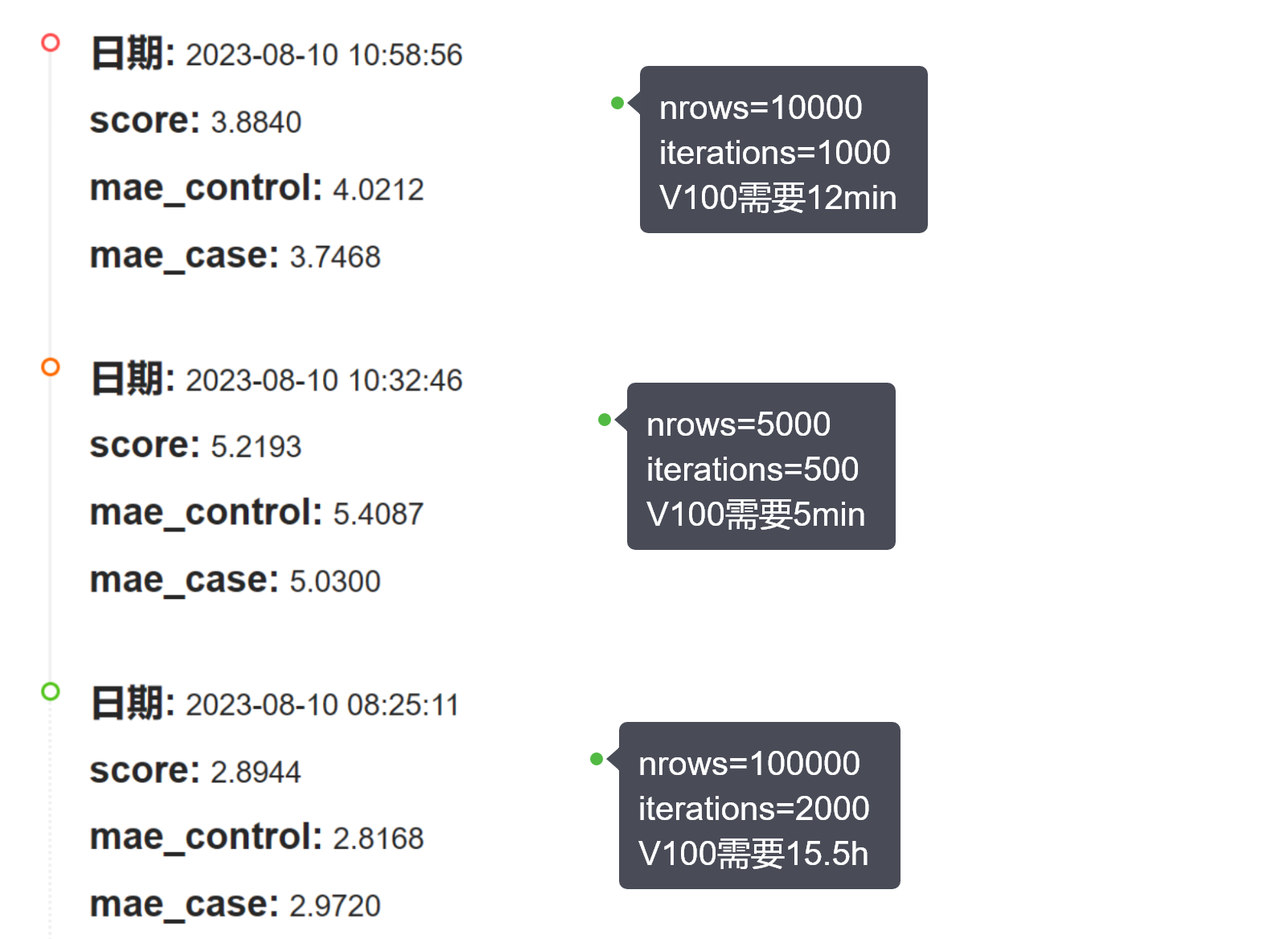
补充
官方比赛时使用的时决策树这种方法,但是年龄时连续的,虽然这里面记录时int数值,但是我觉得可能对连续值使用向下取整数可能更符合,所以我觉得我们可以尝试使用连续值得方法来解决问题。可以尝试一些其他得模型吧。
文档信息
- 本文作者:Xiong
- 本文链接:https://xiongsircool.github.io/xiongbook/2023/08/18/aliyungame/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)